
参考 Pixeled – Creating a Compiler
一、简述编译
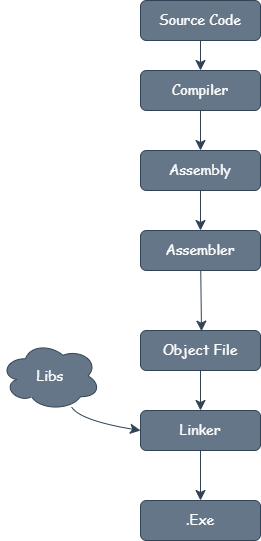
简单来讲,C++/ C/ Rust 此类编译型编程语言的编译过程基本都遵循以下流程:
- 编译器(Compiler)将高级语言源代码转换为平台相关的汇编语言(Assembly Code)
- 汇编器(Assembler)将汇编语言的符号化指令逐条映射为二进制机器码(Machine Code)
- 机器码 可直接被 CPU 解码执行,构成最终可执行文件的核心指令集
我们能编写的最简单的 C++ 程序是这样的
int main(void)
{
return 0;
}
对于这个 C++ 程序,其汇编程序
global _start
_start:
mov rax, 60
mov rdi, 0
syscall
这段代码中,我们将系统调用号 60(exit)存入 rax 寄存器,将退出状态码 0 存入 rdi 寄存器。最后由 syscall触发系统调用,执行exit(0)
| NR | syscall name | references | %rax | arg0 (%rdi) | arg1 (%rsi) | arg2 (%rdx) | arg3 (%r10) | arg4 (%r8) | arg5 (%r9) |
|---|---|---|---|---|---|---|---|---|---|
| 60 | exit | man/ cs/ | 0x3c | int error_code | – | – | – | – | – |
nasm -f elf64 program.asm -o program.o # 汇编为 x86-64 目标文件
ld program.o -o program # 链接生成可执行文件
./program # 运行程序
echo $? # 输出 0
二、理论
1. 开始
工具链
WSL2 + VSCode + CMake
我们用 C++ 来创建一个简单的编译器程序,给项目起一个好听的名字是很有必要的。
# 创建项目目录
sentomk@MSI:~/code$ mkdir kinglet && cd kinglet
sentomk@MSI:~/code/kinglet$ code .
项目结构如下
kinglet/
├── CMakeLists.txt
├── src/
└── main.cpp
确保 CMake 文件在根目录!!!
2. CMake工程配置
cmake_minimum_required(VERSION 3.21)
project(kinglet
LANGUAGES CXX
)
set(CMAKE_CXX_STANDARD 20)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
set(CMAKE_CXX_EXTENSIONS OFF)
add_executable(klet src/main.cpp)
假设现在src/main.cpp中已有如下内容
#include <iostream>
int main()
{
std::cout << "Hello World" << std::endl;
return 0;
}
使用 CMake 构建项目
# 创建并进入构建目录
sentomk@MSI:~/code/kinglet$ mkdir build && cd build
# 生成构建系统
sentomk@MSI:~/code/kinglet/build$ cmake ..
-- The CXX compiler identification is GNU 13.3.0
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: /usr/bin/c++ - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Configuring done (2.2s)
-- Generating done (0.0s)
-- Build files have been written to: /home/sentomk/code/kinglet/build
# 使用 make 命令编译
sentomk@MSI:~/code/kinglet/build$ make
[ 50%] Building CXX object CMakeFiles/klet.dir/src/main.cpp.o
[100%] Linking CXX executable klet
[100%] Built target klet
# 运行
sentomk@MSI:~/code/kinglet/build$ ./klet
Hello World
3. 创造我们自己的语言
我希望最终创造出的编译器可以读取一个.kl后缀的文件,这是我们自己发明的编程语言(虽然一开始他几乎没有任何功能…)
现在项目结构如下
kinglet/
├── CMakeLists.txt
├── src/
| └── main.cpp
└── build
└── test.kl
test.kl
return 0;
4. 再谈编译
一般来说,编译流程大致可以细分为七个阶段
Ⅰ. 词法分析 (Lexical Analysis)
词法分析是计算机科学中将字符序列转换为标记(token)序列的过程。进行词法分析的程序或者函数叫作词法分析器(lexical analyzer,简称lexer),也叫扫描器(scanner)。词法分析器一般以函数的形式存在,供语法分析器调用
- 输入:源代码字符流
- 输出:Token 序列
标记
此处所指的标记是一个字符串,是构成源代码的最小单位。从输入字符流中生成标记的过程叫作标记化(tokenization),在这个过程中,词法分析器还会对标记进行分类。
词法分析器通常不会关心标记之间的关系(这属于语法分析的范畴),举例来说:词法分析器能够将括号识别为标记,但并不保证括号是否匹配。
例如下列 C++ 表达式sum=3+2;
将其标记化后可以得到下表内容:
| 语素 | 标记类型 |
|---|---|
| sum | 标识符 |
| = | 赋值操作符 |
| 3 | 数字 |
| + | 加法操作符 |
| 2 | 数字 |
| ; | 语句结束 |
简单来说就是从文件中提取所有字符
Ⅱ. 语法分析 (Syntax Analysis)
语法分析是根据某种给定的形式文法对由单词序列(如英语单词序列)构成的输入文本进行分析并确定其语法结构的一种过程。
语法分析器通常是作为编译器或解释器的组件出现的,它的作用是进行语法检查、并构建由输入的单词组成的数据结构(一般是语法分析树、抽象语法树等层次化的数据结构)。语法分析器通常使用一个独立的词法分析器从输入字符流中分离出一个个的“单词”,并将单词流作为其输入。实际开发中,语法分析器可以手工编写,也可以使用工具(半)自动生成。
- 输入:Token 序列
- 输出:抽象语法树 (AST)
语法分析器一般分为两类:
- 自顶向下分析
- 自底向上分析
Ⅲ. 语义分析 (Semantic Analysis)
语义分析是将句法结构关联起来的过程,从单词、短语、从句、句子和段落的层面到整个写作的层面,再到它们独立于语言的含义。
核心任务:
- 类型检查(静态类型语言需严格验证)
- 符号表构建(记录变量/函数信息)
- 作用域验证(如变量是否先声明后使用)
| 符号表示例: | 名称 | 类型 | 作用域 | 内存偏移 |
|---|---|---|---|---|
| x | int | global | 0x1000 | |
| func | (int)→void | global | – |
本节中暂且不谈剩下这些部分:
Ⅳ. 中间代码生成 (Intermediate Code Generation)
Ⅴ. 代码优化 (Optimization)
Ⅵ. 目标代码生成 (Code Generation)
Ⅶ. 目标代码优化 (Target-Specific Optimization)
三、编写程序
1. 读取文件
在编译器开发中,文件读取是首个关键步骤。因此我们需要获取 test.kl(或用户指定的其它源文件)中的代码内容,为后续的词法分析、语法分析等阶段做准备。
1.1 参数校验与程序框架
在 CMakeLists 中我们通过 add_executable(klet ...) 指定构建目标名称为 klet,编译后将生成名为 klet(Unix/Linux)或 klet.exe(Windows)的可执行文件,这正是我们的编译器程序。因此运行时需要两个命令行参数:
- 程序自身路径(自动通过
argv[0]获取) - 待编译的源文件路径(由用户通过
argv[1]指定)
对应的参数校验逻辑应检查argc == 2,确保用户正确输入了源文件路径。
#include <iostream>
int main(int argc, char *argv[])
{
if (argc != 2)
{
std::cerr << "Incorrect usage. Correct usage is..." << std::endl;
std::cerr << "klet <input.kl>" << std::endl;
return 1;
}
std::cout << "Compiler is ready!" << std::endl;
}
1.2 文件读取实现
#include <iostream>
#include <fstream>
#include <sstream>
std::string readFile(const std::string &path)
{
std::ifstream input(path, std::ios::in);
if (!input.is_open())
{
throw std::runtime_error("Cannot open that file : " + path);
}
std::stringstream buf;
buf << input.rdbuf();
return buf.str();
}
int main(int argc, char *argv[])
{
if (argc != 2)
{
std::cerr << "Usage: ./klet <input.kl>n";
return EXIT_FAILURE;
}
std::string contents;
try
{
contents = readFile(argv[1]);
}
catch (const std::exception &e)
{
std::cerr << e.what() << 'n';
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}
2. 词法分析
激动人心的一步,我们终于要开始干正事了。再次说明,所谓词法分析就是将字符序列转换为标记序列的过程。看看我们的源文件
return 0;
对于这段简单的语句,能看到出现了print关键字、整型数字、数学运算符以及分号,空格在这里不必特别关照,读到时跳过即可。因此其词法分析后的标记列表如下
_RETURN
INT_LIT
SEMI
我们用一个枚举(enum)来存储这些标记类型,并用一个结构体包含标记的类型与值
enum TokenType
{
_RETURN,
INT_LIT,
SEMI
};
struct Token
{
TokenType type;
std::optional<std::string> value = std::nullopt;
};
optional是 C++17中引入的新标准,这种存储值的方法的优点是对于SEMI这类无需附加值的终结符,optional通过栈上内存的惰性分配避免无意义的内存占用。且可以有效避免使用nullptr等危险的空值表示。
2.1 字符预读与索引管理
原理
词法分析器(Lexer)的核心任务是将输入的字符流转换为有意义的 Token 流。在此过程中,需要两个关键操作:
- 探查(Peek):查看当前位置前方(未读取)的字符,但不移动指针。用于确定后续字符的类型(例如判断
=是赋值还是==)。 - 消费(Consume):读取当前字符并移动指针到下一个位置。用于逐步遍历输入流。
设计
1.
peek方法- 返回值:
std::optional<char>,越界时返回空(std::nullopt),否则返回字符。 - 参数:
ahead表示向前预读的步长。 - 边界检查:若
m_index + ahead超出字符串长度,返回空
- 返回值:
2. consume 方法
- 返回值:当前字符(
char)。 - 副作用:递增索引
m_index++,指向下一个字符。 - 异常安全:若索引越界,
std::string::at抛出std::out_of_range
private:
[[nodiscard]] std::optional<char> peek(const int ahead = 1) const
{
if (m_index + ahead > m_src.length())
{
return {}; // 越界返回空
}
else
{
return m_src.at(m_index);
}
}
char consume()
{
return m_src.at(m_index++);
}
2.2 Token 流生成
前面说到,一个词法分析器应该具备将输入字符串分解为一系列 Token(如关键字、数组、符号等)的功能。我们编写一个tokenize方法实现这一关键步骤
针对我们目前需要处理的这一行语句return 0;,代码逻辑结构可以设计如下:
tokenize()
├── 初始化 tokens 和 buf
├── while (未扫描完所有字符)
│ ├── 如果是字母(标识符或关键字)
│ │ ├── 消费连续字母数字字符 → 存入 buf
│ │ └── 如果 buf 是 "return" → 生成 _RETURN Token,否则报错
│ ├── 如果是数字(整数)
│ │ ├── 消费连续数字 → 存入 buf
│ │ └── 生成 INT_LIT Token
│ ├── 如果是分号 `;`
│ │ └── 生成 SEMI Token
│ ├── 如果是空白字符
│ │ └── 跳过
│ └── 其他字符 → 报错退出
└── 返回 tokens
1. 处理字母
if (std::isalpha(peek().value()))
{
buf.push_back(consume());
while (peek().has_value() && std::isalnum(peek().value()))
{
buf.push_back(consume());
}
if (buf == "return")
{
tokens.push_back({TokenType::_RETURN});
buf.clear();
continue;
}
else
{
std::cerr << "Wrong!" << std::endl;
exit(EXIT_FAILURE);
}
}
2. 处理数字
else if (std::isdigit(peek().value()))
{
buf.push_back(consume());
while (peek().has_value() && std::isdigit(peek().value()))
{
buf.push_back(consume());
}
tokens.push_back({TokenType::INT_LIT, buf});
buf.clear();
}
3. 处理分号
else if (peek().value() == ';')
{
consume();
tokens.push_back({TokenType::SEMI});
continue;
}
4. 处理空白字符(空格)
else if (std::isspace(peek().value()))
{
consume();
continue;
}
3. 输出汇编文件
我们编写一个方法将token流转写为汇编语言
std::string tokens_to_asm(const std::vector<Token> &tokens)
{
std::stringstream output;
output << "global _startn_start:n";
for (int i = 0; i < tokens.size(); ++i)
{
const Token &token = tokens.at(i);
if (token.type == TokenType::_RETURN)
{
if (i + 1 < tokens.size() && tokens.at(i + 1).type == TokenType::INT_LIT)
{
if (i + 2 < tokens.size() && tokens.at(i + 2).type == TokenType::SEMI)
{
output << " mov rax, 60n";
output << " mov rdi, " << tokens.at(i + 1).value.value() << "n";
output << " syscall";
}
}
}
}
return output.str();
}
源代码可在 TinyCompilerOfShame获取